👨🏫Ollama+Xinference+Speakr 搭建会议纪要助手
AI-摘要
JinzAI GPT
AI初始化中...
介绍自己
生成本文简介
推荐相关文章
前往主页
前往tianli博客
1.使用Ollama部署大语言模型
此处较为简单,前面的文章有教程,不再赘述.
2.使用Xinference部署whisper-large-v3
2.1部署Xinference
docker 部署命令:
docker run -v </on/your/host>:</on/the/container> -e XINFERENCE_HOME=</on/the/container> -p 9998:9997 --gpus all xprobe/xinference:latest xinference-local -H 0.0.0.02.2使用Xinference部署whisper-large-v3
部署Xinference成功后如下图:
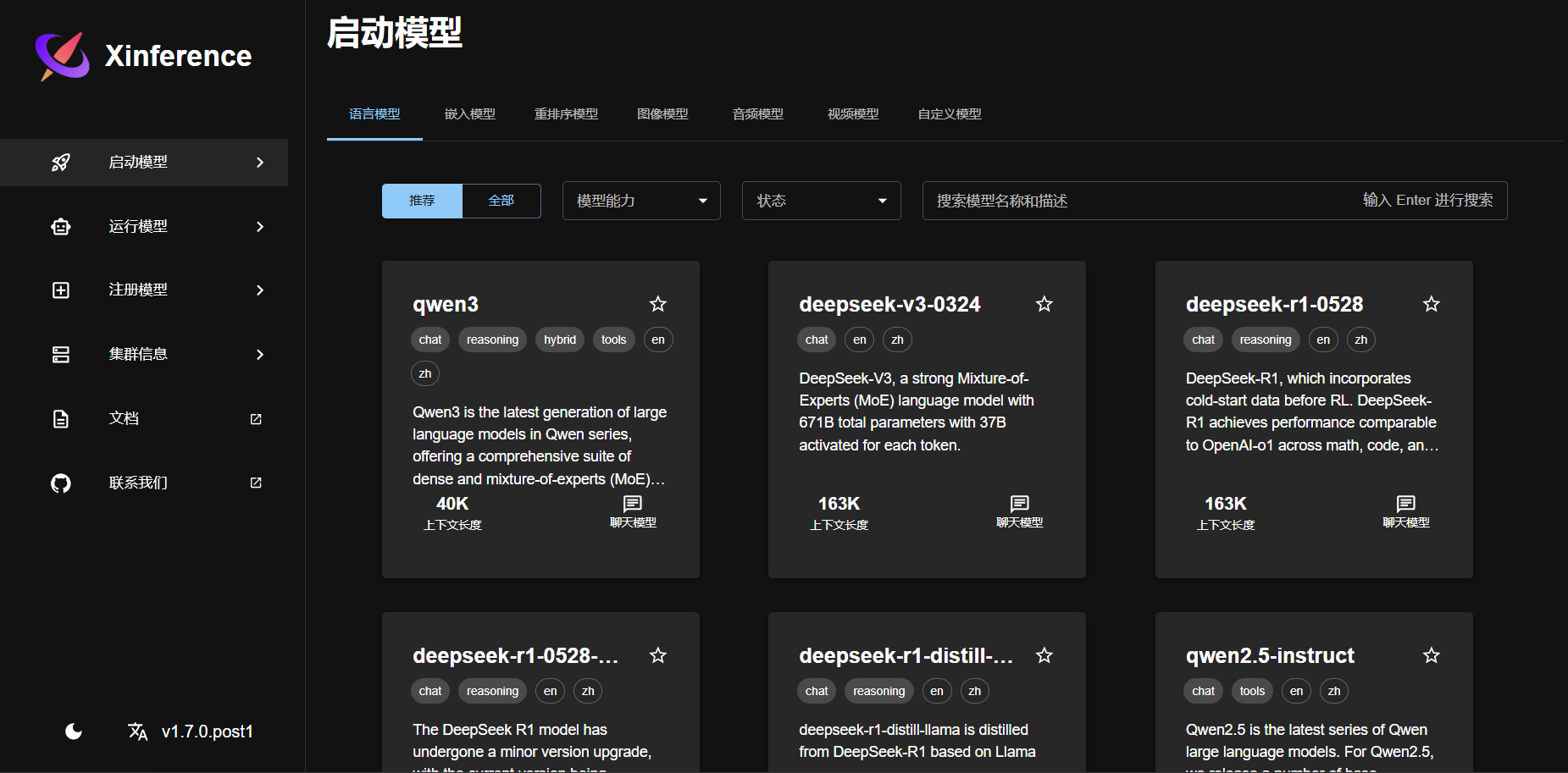
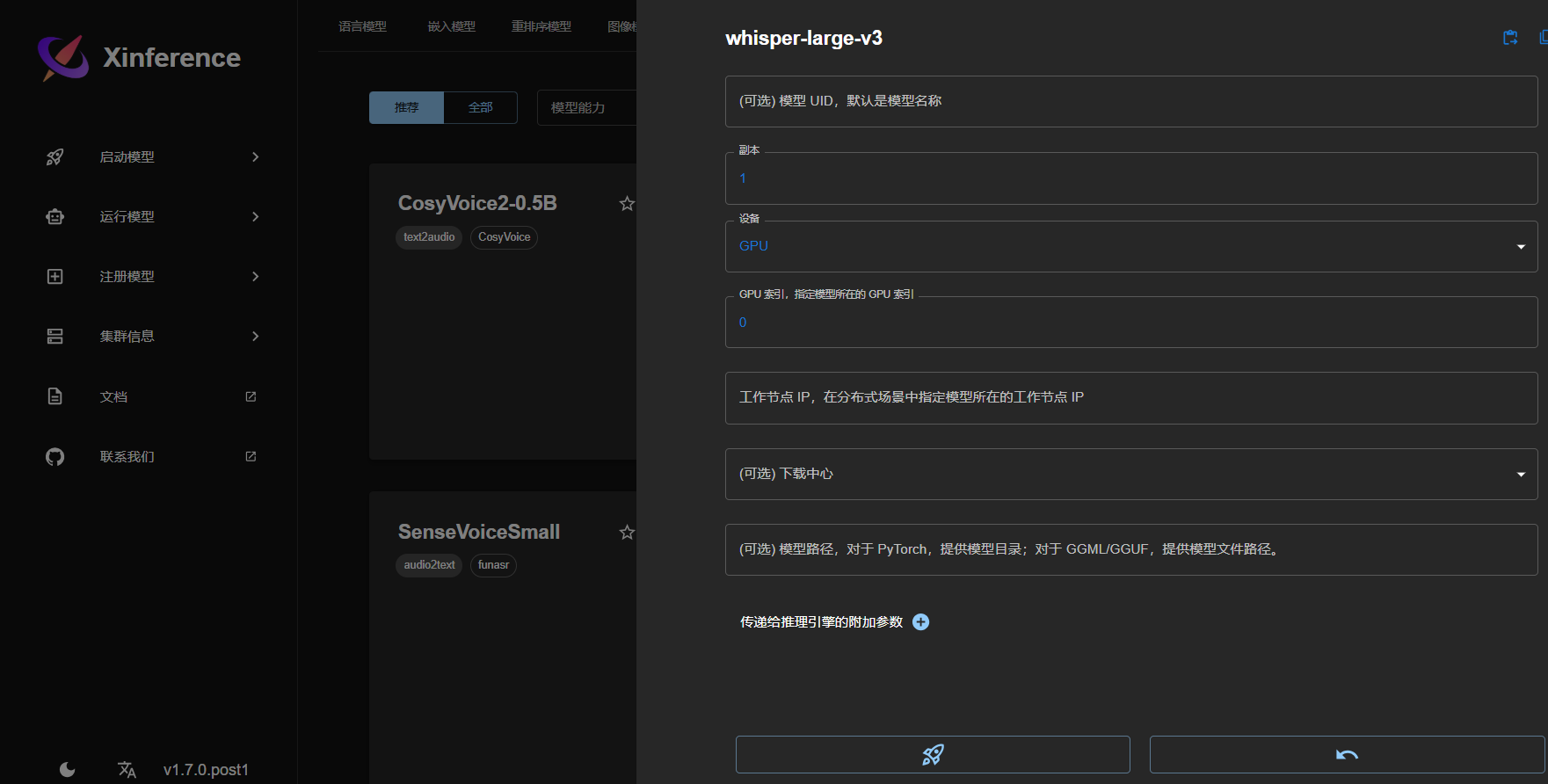
此时只需要选择你想要部署的模型,点击后选择你想要哪个index 的GPU运行模型,之后点击🚀即可运行
3.Speakr部署
Speakr地址->Speakr
本次部署共使用到两个文件:docker-compose.yml 和 .env文件
docker-compose.yml文件简要配置如下:
services:
app:
image: learnedmachine/speakr:latest
container_name: speakr
restart: unless-stopped
ports:
- "8899:8899"
env_file:
- .env
volumes:
- ./uploads:/data/uploads
- ./instance:/data/instanceroot.env文件简要配置如下:
# --- Text Generation Model (uses /chat/completions endpoint) ---
TEXT_MODEL_BASE_URL=http://10.8.11.36:11434/v1
TEXT_MODEL_API_KEY=your_openrouter_api_key
TEXT_MODEL_NAME=deepseek-r1:70b
# --- Transcription Service (uses /audio/transcriptions endpoint) ---
TRANSCRIPTION_BASE_URL=http://10.8.11.36:9998/v1
TRANSCRIPTION_API_KEY=your_openai_api_key
WHISPER_MODEL=whisper-large-v3
# --- Application Settings ---
ALLOW_REGISTRATION=false
SUMMARY_MAX_TOKENS=8000
CHAT_MAX_TOKENS=5000
# --- Admin User (created on first run) ---
ADMIN_USERNAME=admin
[email protected]
ADMIN_PASSWORD=Jiiactco@123
# --- Docker Settings (rarely need to be changed) ---
SQLALCHEMY_DATABASE_URI=sqlite:////data/instance/transcriptions.db
UPLOAD_FOLDER=/data/uploads4.录音按钮
搭建完成之后,界面如下:
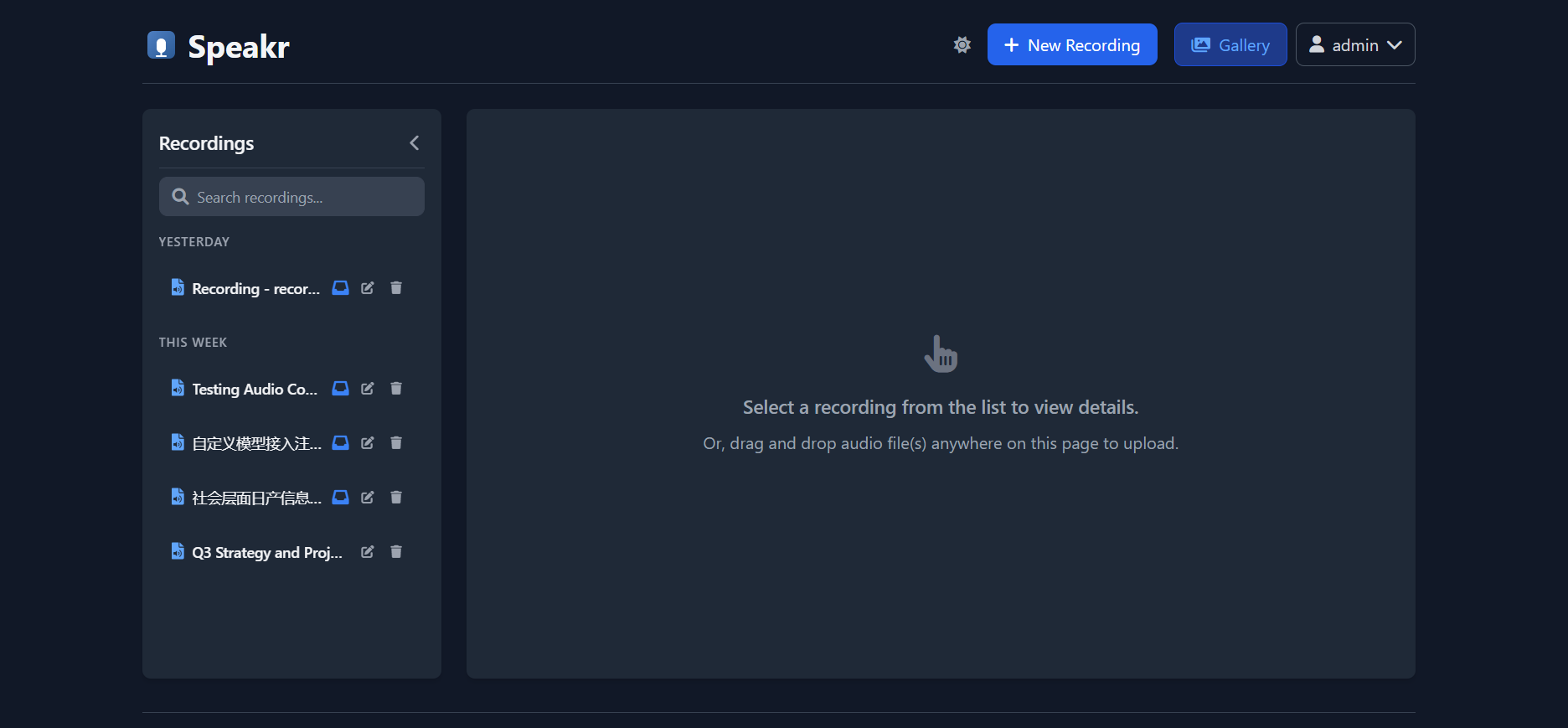
可以通过录音或者拖入音频文件来做会议音频转文字,并通过LLM来做会议纪要.
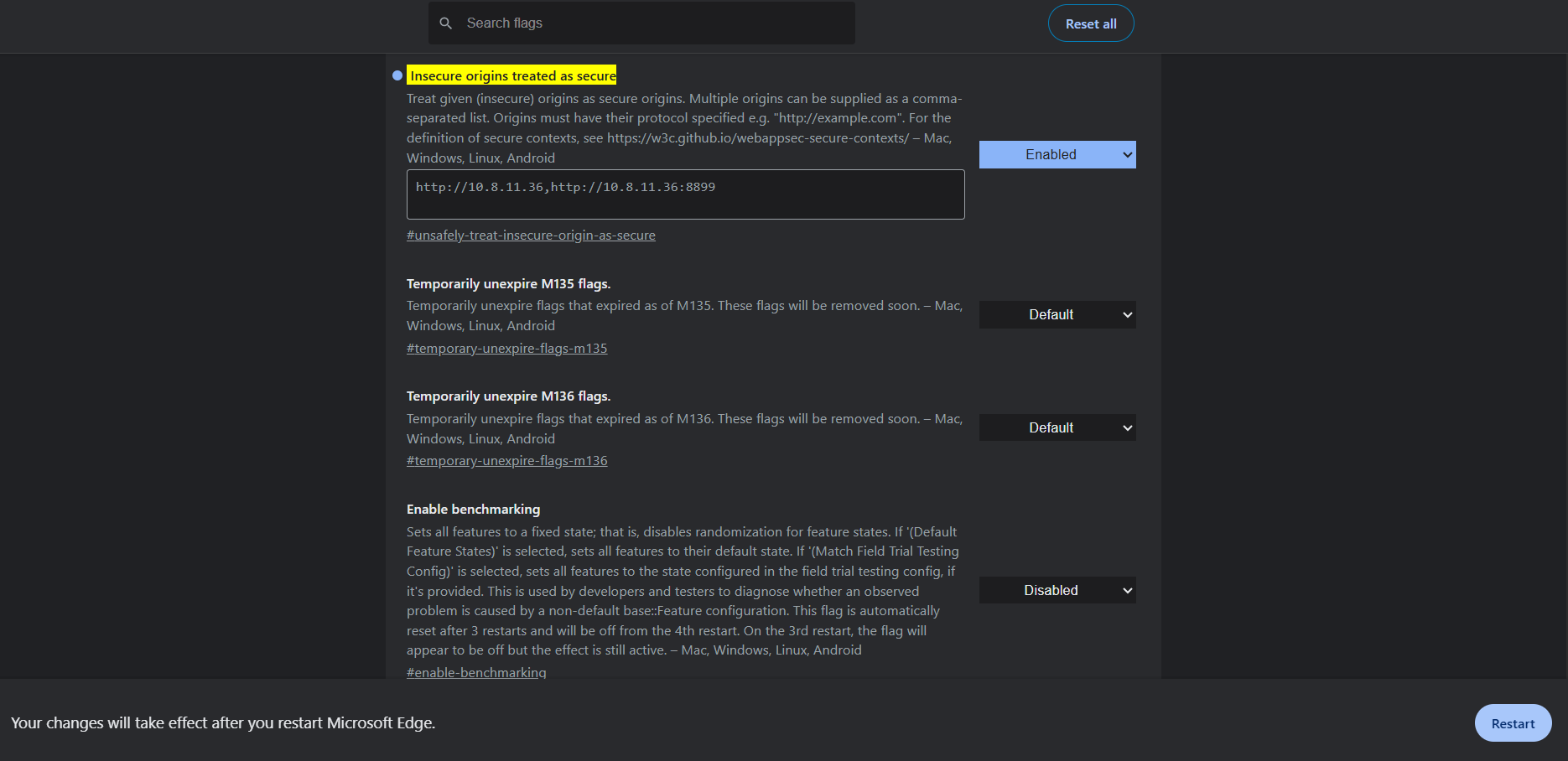
但是可能有时候没有下图中的录音按钮:
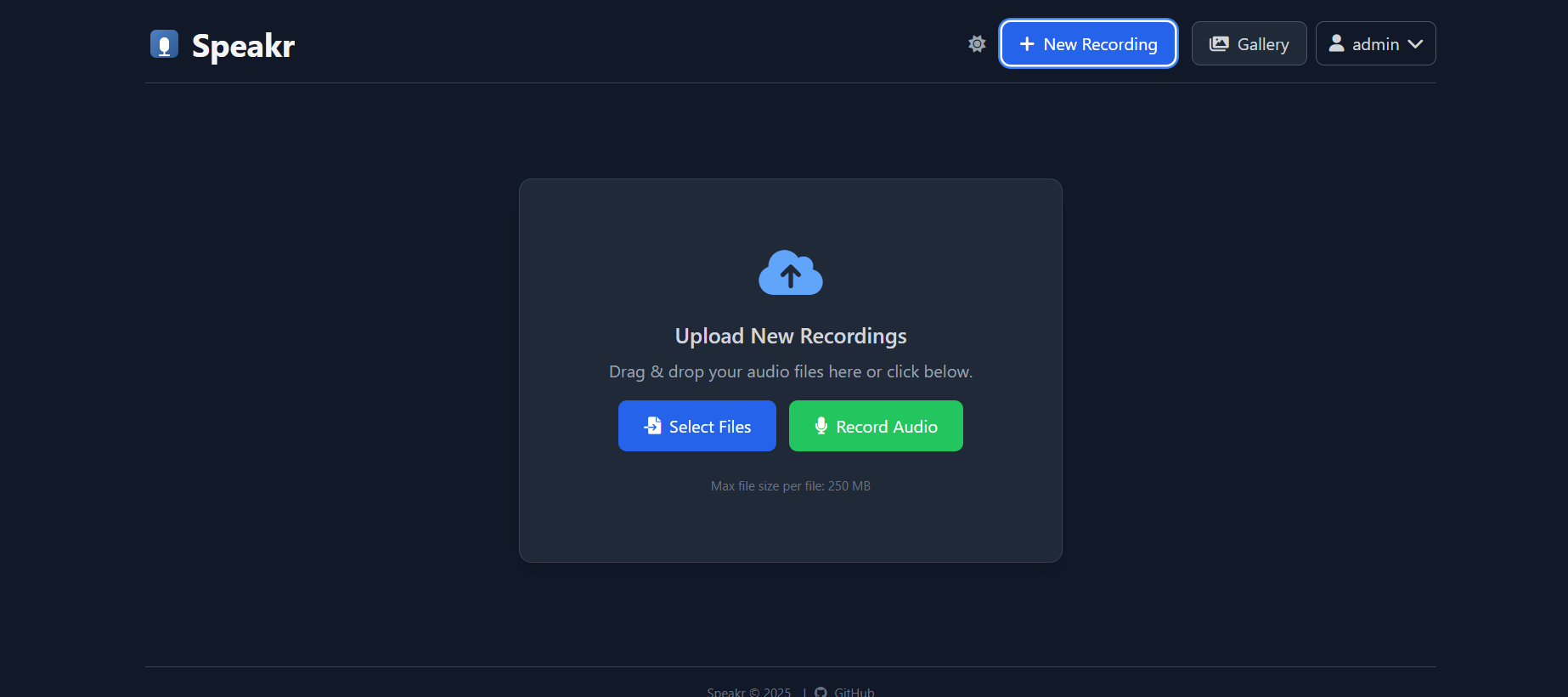
此时需要访问:
chrome://flags/#unsafely-treat-insecure-origin-as-secure将下图中的 Insecure origins treated as secure 设置为 Enabled
然后将许可的IP和端口填入,再点击右下角的 Restart 按钮即可

阅读建议

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果