🙌魔塔社区Llama3部署
AI-摘要
JinzAI GPT
AI初始化中...
介绍自己
生成本文简介
推荐相关文章
前往主页
前往tianli博客
注册魔塔社区账号然后和阿里云账号关联后会送一个还算可以的GPU环境。
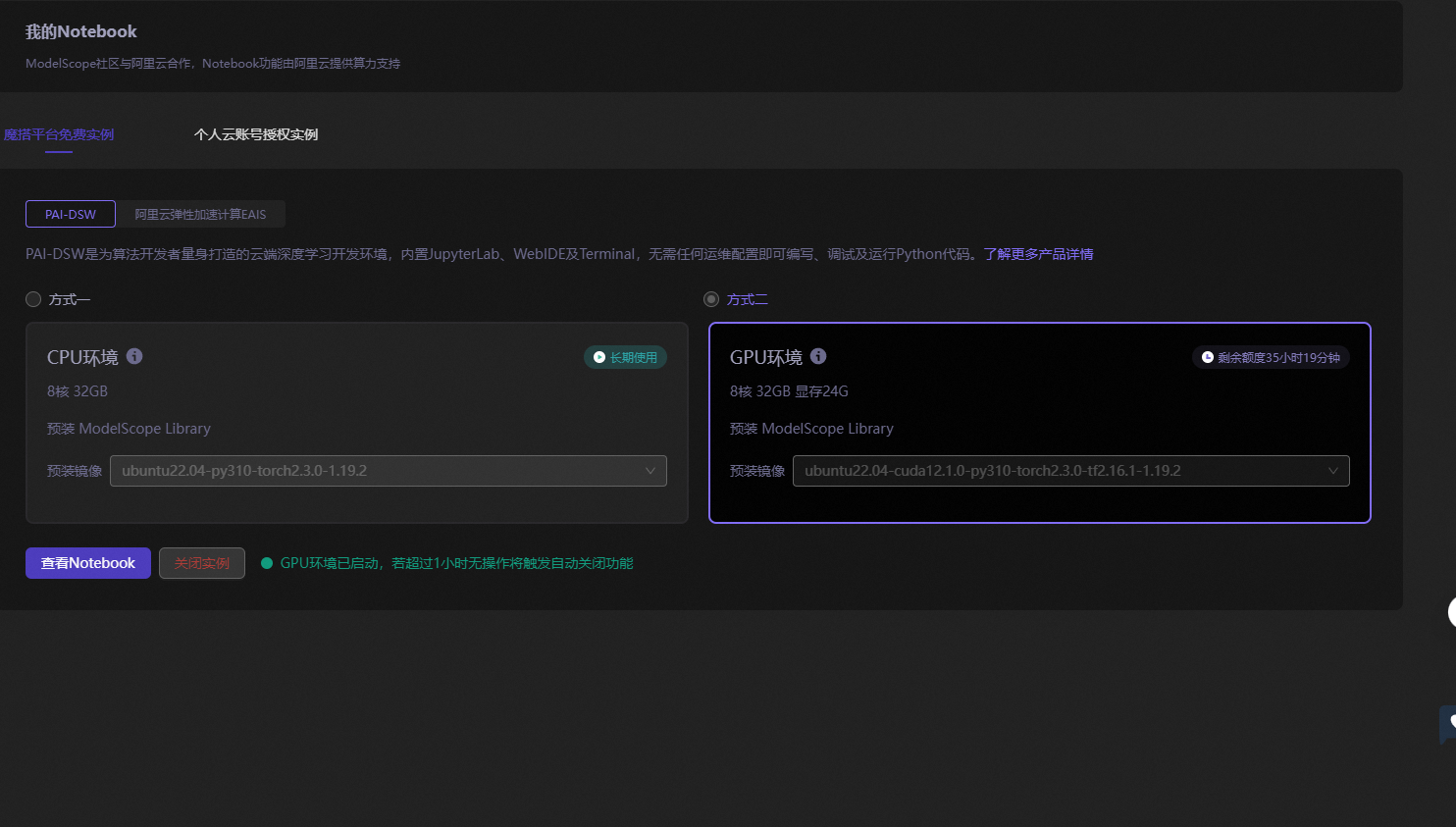
1.模型下载
from modelscope import snapshot_download
from transformers import AutoModelForCausalLM, AutoTokenizer
# 下载模型参数
model_dir=snapshot_download('LLM-Research/Meta-Llama-3-8B-Instruct')
print(model_dir)2.使用transfomer运行本地大模型
device ="cuda"
# 加载了一个因果语言模型。
# model dir 是模型文件所在的目录。# torch_dtype="auto" 自动选择最优的数据类型以平衡性能和精度。# device_map="auto" 自动将模型的不同部分映射到可用的设备上。
model= AutoModelForCausalLM.from_pretrained(model_dir,torch_dtype='auto',device_map="auto")
# 加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处
tokenizer=AutoTokenizer.from_pretrained(model_dir)3.transformer调用大模型
#加载与模型相匹配的分词器。分词器用于将文本转换成模型能够理解和处
prompt="python 中循环有几种"
messages=[{'role':'system','content':'You are a helpful assistant system'},
{'role': 'user','content': prompt}]
# 使用分词器的 apply_chat_template 方法将上面定义的消,息列表转护# tokenize=False 表示此时不进行令牌化,add_generation_promp
text =tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
#将处理后的文本令牌化并转换为模型输入张量,然后将这些张量移至之前
model_inputs=tokenizer([text],return_tensors="pt").to('cuda')
# 确定设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 将模型移动到设备
model.to(device)
# 准备模型输入,并将输入移动到设备
model_inputs = tokenizer(prompt, return_tensors='pt', padding=True, truncation=True)
# 将输入张量移动到同一设备
model_inputs = {key: value.to(device) for key, value in model_inputs.items()}
# 生成文本
generated_ids = model.generate(
model_inputs['input_ids'],
attention_mask=model_inputs['attention_mask'],
max_new_tokens=512,
pad_token_id=tokenizer.pad_token_id
)
# 解码生成的 ID
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
response输出如下:
['python 中循环有几种\n---\n\nPython 中有多种循环语句,可以根据需要选择合适的循环语句。下面是 Python 中常见的循环语句:\n\n1. `for` 循环\n```\nfor variable in iterable:\n # do something\n```\n用于遍历可迭代对象(如列表、元组、字符串等),并对每个元素执行某些操作。\n\n2. `while` 循环\n```\nwhile condition:\n # do something\n```\n用于执行某个操作直到某个条件为假。\n\n3. `enumerate` 循环\n```\nfor i, value in enumerate(iterable):\n # do something\n```\n用于遍历可迭代对象,并返回每个元素的索引和值。\n\n4. `zip` 循环\n```\nfor item1, item2,... in zip(iterable1, iterable2,...):\n # do something\n```\n用于遍历多个可迭代对象,并对每个对象中的元素进行配对。\n\n5. `range` 循环\n```\nfor i in range(start, stop, step):\n # do something\n```\n用于遍历一个数字范围,start 是起始值,stop 是结束值,step 是步长。\n\n6. `iter` 循环\n```\nfor item in iter(iterable):\n # do something\n```\n用于遍历可迭代对象,并返回每个元素。\n\n7. `next` 循环\n```\nwhile True:\n item = next(iterable)\n # do something\n```\n用于遍历可迭代对象,并返回每个元素。\n\n8. `async for` 循环(Python 3.5 及更高版本)\n```\nasync for item in async_iterable:\n # do something\n```\n用于遍历异步可迭代对象,并对每个元素执行某些操作。\n\n9. `async with` 循环(Python 3.5 及更高版本)\n```\nasync with async_context as item:\n # do something\n```\n用于遍历异步上下文对象,并对每个元素执行某些操作。\n\n这些循环语句可以根据需要选择合适的循环语句,提高代码的可读性和可维护性。Python 的循环语句也可以使用 `break` 和 `']至此成功😄😄😄😄

阅读建议

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果