机器学习系列-1.基本概念
1.什么是机器学习
对于给定的任务T(Task),在合理的性能度量方案P(Performance)的前提下,某计算机程序可以自主学习任务T的经验E(Experience);随着提供合适、优质、大量的经验E,该程序对于任务T的性能P逐步提高
这里最重要的是机器学习的对象:
任务Task, T,一个或者多个
经验Experience, E
性能Performance,P
随着任务的不断执行,经验的积累会带来计算机性能的提升 - Tom Michale Mitchell, 1997
换个表述:机器学习是人工智能 AI(Artificial Intelligence)的一个分支。我们使用计算机设计一个系统,使它能够根据提供的训练数据按照一定的方式来学习(Learning);随着训练次数的增加,该系统可以在性能上不断地学习和改进;通过参数优化的学习模型,能够用于预测相关问题的输出。
2.人工智能AI、机器学习、深度学习之间的关系
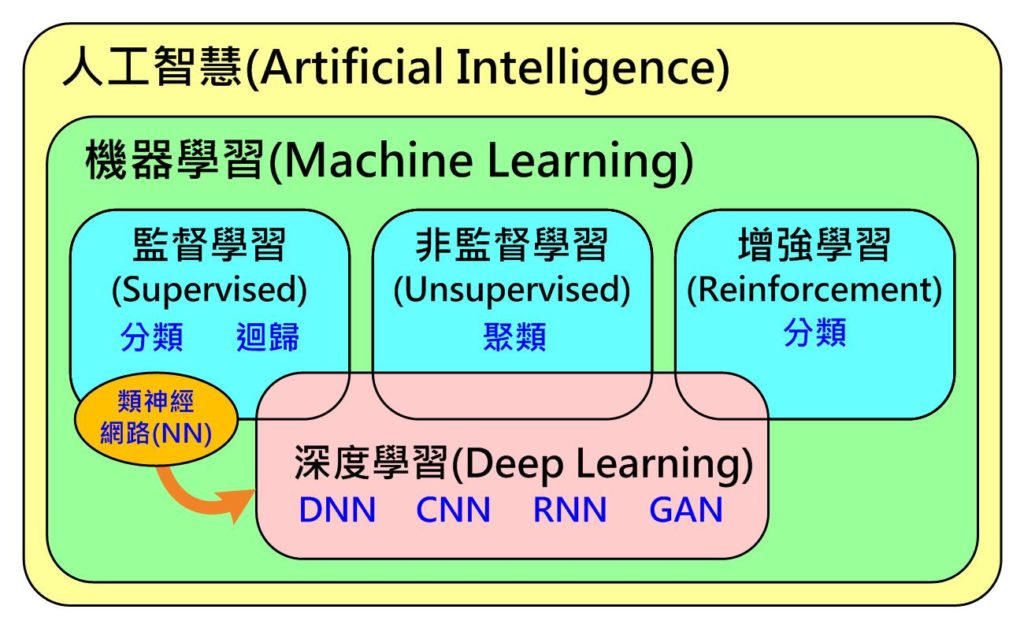
监督学习(Supervised Learning):输入数据由输入特征值和目标值组成。函数的输出可以是一个连续的值(回归),或是输出有限个离散值(分类)。
深度学习(Deep Learning):基于样本数据通过一定的训练方法得到包含多个层级的深度网络结构的机器学习过程。
无监督学习(Unsupervised Learning):输入的数据由输入特征值组成,没有目标值。
输入的数据没有被标记,也没有确定的结果。样本数据类别未知。
需要根据样本间的相似性对样本集进行类别划分。
增强学习(Reinforcement Learning):实质是make decisions问题。自动进行决策,并且可以做连续决策。
我的理解:是否为监督学习,主要却决于输入数据是否有标签(label),全部都有即为监督学习,全部都没有即为无监督学习,部分有即为半监督学习(Semi-Supervised Learning)。
3.有监督学习
features | target | |||||
samples | type | rooms | surface | public trans | sold | |
|---|---|---|---|---|---|---|
Apartment | 3 | 50 | TRUE | 450 | ||
House | 5 | 254 | FALSE | 430 | ||
Duplex | 4 | 68 | TRUE | 712 | ||
Apartment | 2 | 32 | TRUE | 234 | ||
samples | Apartment | 2 | 33 | TRUE | ? | |
House | 4 | 210 | TRUE | ? | ||
以上就是一个有监督学习的例子,根据房子的类型、房间数量、面积和公共交通等特征(feature),以及已有的房子售价,可以在给出的samples上根据模型来预测售价(target)

