机器学习系列-3.梯度下降
AI-摘要
JinzAI GPT
AI初始化中...
介绍自己
生成本文简介
推荐相关文章
前往主页
前往tianli博客
1. Gradient descent (梯度下降)
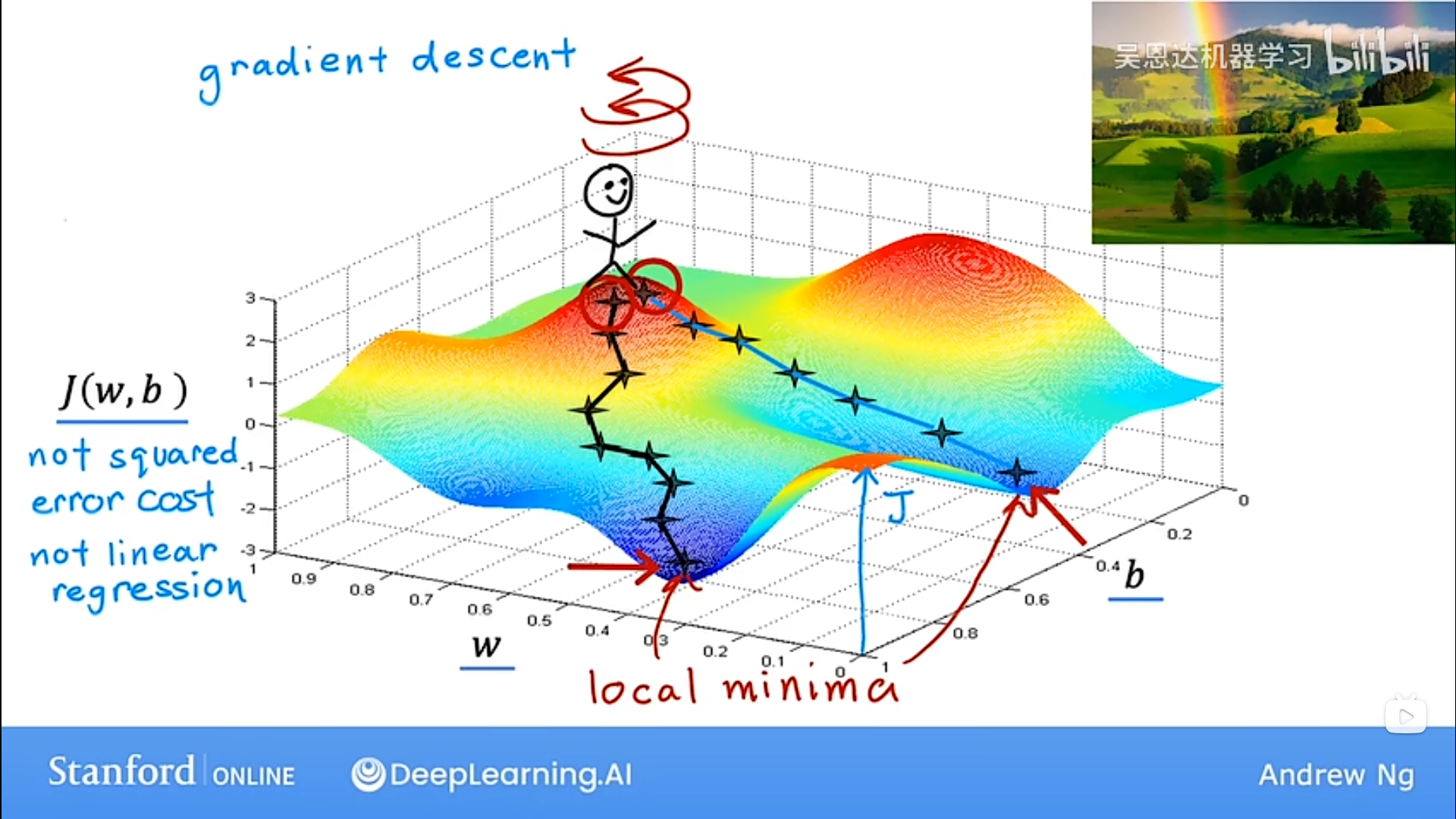
不止针对于J(w,b)代价函数
不止针对于 linear regression 线性回归
可能造成走错了“山谷”后出不来的问题
2. Gradient descent algorithm(梯度下降算法)

α :Learning rate (学习率),下降的”步子“。
过小导致convergence(收敛)太慢,太大容易overshoot
w,b一定要Simultaneous update(同步更新)
3. Local minimum(局部最小值)
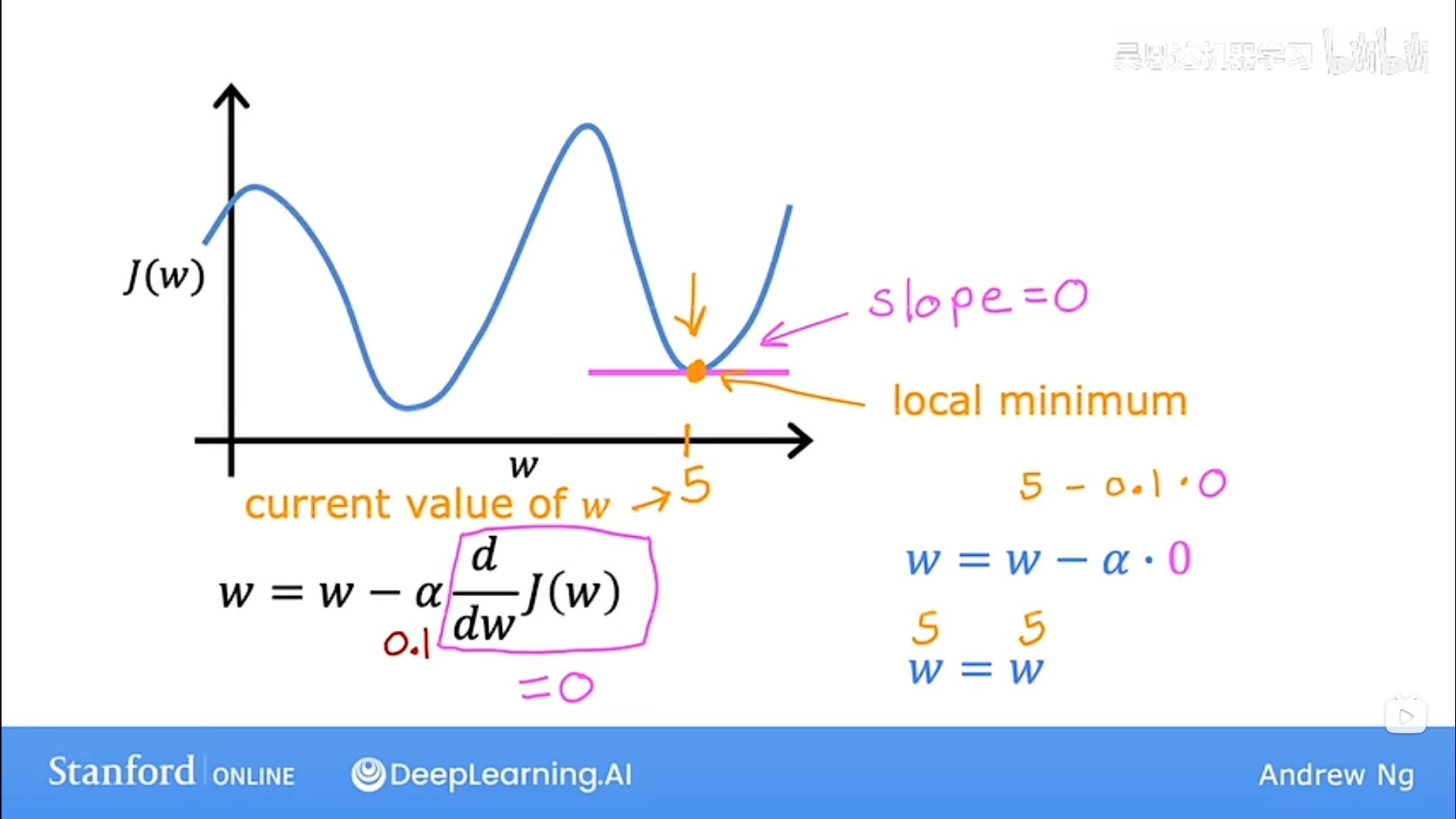
当到达局部最小值后,由于derivative(导数,实际为偏导)为0,w不再更新,梯度下降停止。
4. 线性回归的梯度下降
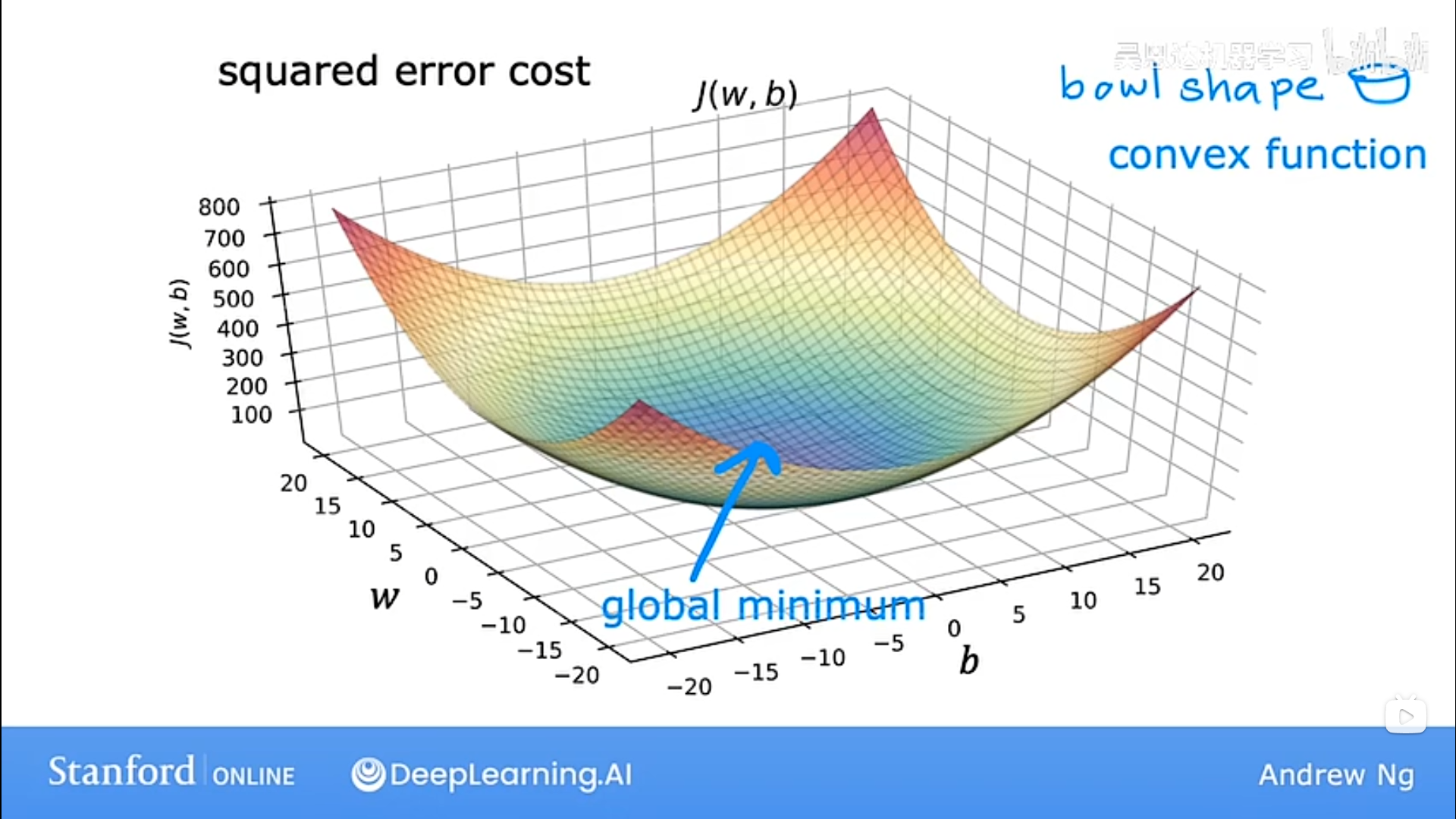
由于线性回归的代价函数J(w,b)呈现为bowl shape,所以又称其为convex function(凸函数),在J(w,b)上实现梯度下降时选择适当的学习率,它总是可以收敛到全局最小值。
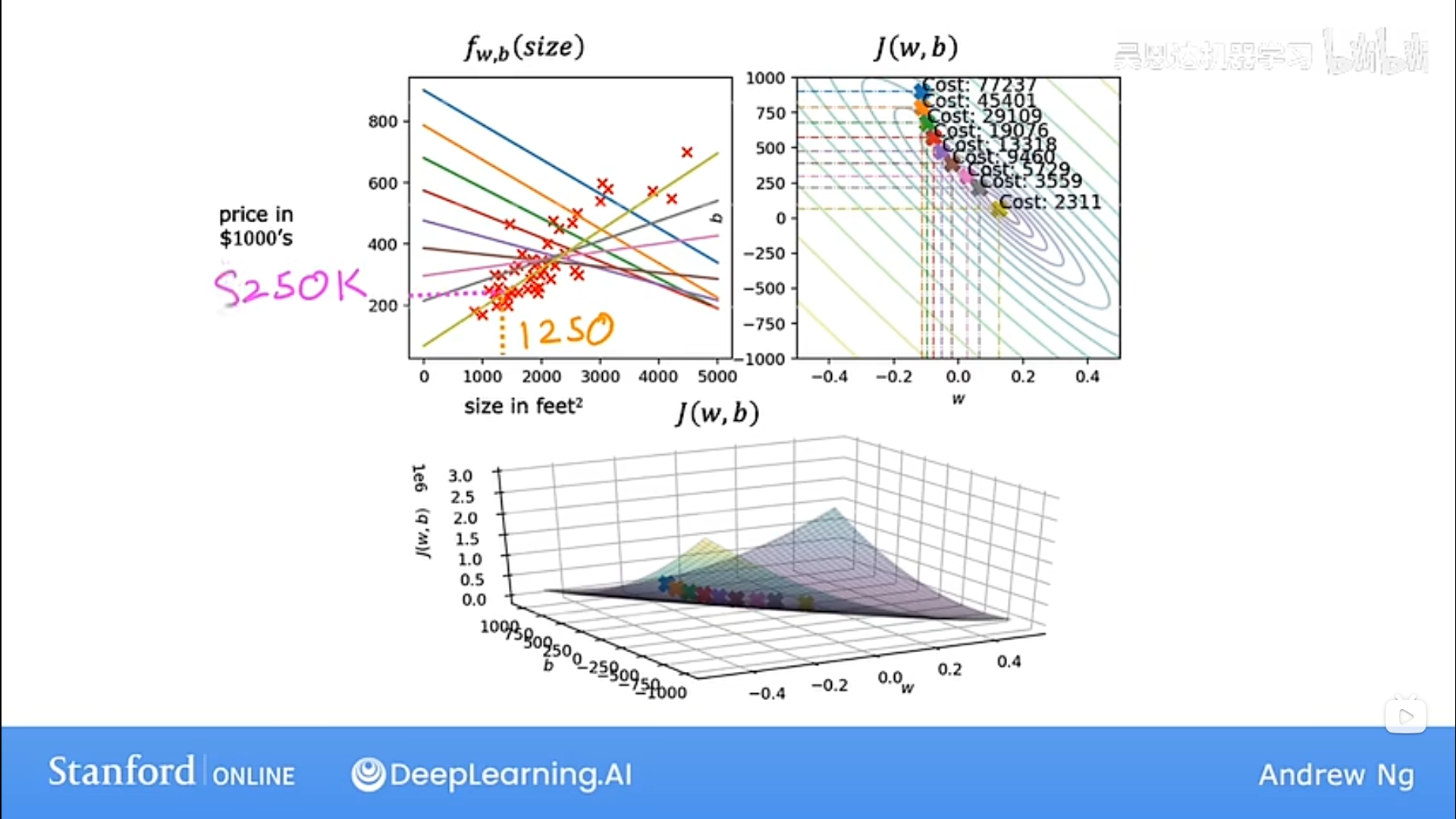
5. 执行梯度下降

阅读建议

评论
匿名评论
隐私政策
你无需删除空行,直接评论以获取最佳展示效果